Testing stochastic code¶
Sometimes code contains an element of randomness, a common example being code that makes use of Monte Carlo methods. Testing this kind of code can be very difficult because if it is run multiple times it will generate different answers, all of which may be “right”, even is it contains no bugs. There are two main ways to tackle testing stochastic code:
Use random number seeds¶
Random number seeds are a little difficult to explain so here’s an example. Here’s a little Python script that prints three random numbers.
import random
# Print three random numbers
print(random.random())
print(random.random())
print(random.random())This script has no bugs but if you run it repeatedly you will get different answers each time. Now let’s set a random number seed.
import random
# Set a random number seed
random.seed(1)
# Print three random numbers
print(random.random())
print(random.random())
print(random.random())Now if you run this script it outputs
0.134364244112
0.847433736937
0.763774618977and every time you run this script you will get the same output, it will print the same three random numbers. If the random number seed is changed you will get a different three random numbers:
0.956034271889
0.947827487059
0.0565513677268but again you will get those same numbers every time the script is run in the future.
Random number seeds are a way of making things reliably random. However a risk with tests that depend on random number seeds is they can be brittle. Say you have a function structured something like this:
def my_function():
a = calculation_that_uses_two_random_numbers()
b = calculation_that_uses_five_random_numbers()
c = a + bIf you set the random number seed you will always get the same value of c, so it can be tested.
But, say the model is changed and the function that calculates a uses a different number of random numbers that it did previously.
Now not only will a be different but b will be too, because as shown above the random numbers outputted given a random number seed are in a fixed order.
As a result the random numbers produced to calculate b will have changed.
This can lead to tests failing when there is in fact no bug.
Measure the distribution of results¶
Another way to test code with a random output is to run it many times and test the distribution of the results. Perhaps the result may fluctuate a little, but is always expected around 10 within some tolerance. That can be tested. The more times the code is run the more reliable the average and so the result. However the more times you run a piece of code the longer it will take your tests to run, which may make tests prohibitively time-consuming to conduct if a reliable result is to be obtained. Furthermore, there will always be an element of uncertainty and if the random numbers happen to fall in a certain way you may get result outside of the expected tolerance even if the code is correct.
Both of these approaches to testing stochastic code can still be very useful, but it is important to also be aware of their potential pitfalls.
Tests that are difficult to quantify¶
Sometimes (particularly in research) the outputs of code are tested according to whether they “look” right. For example say we have a code modelling the water levels in a reservoir over time.
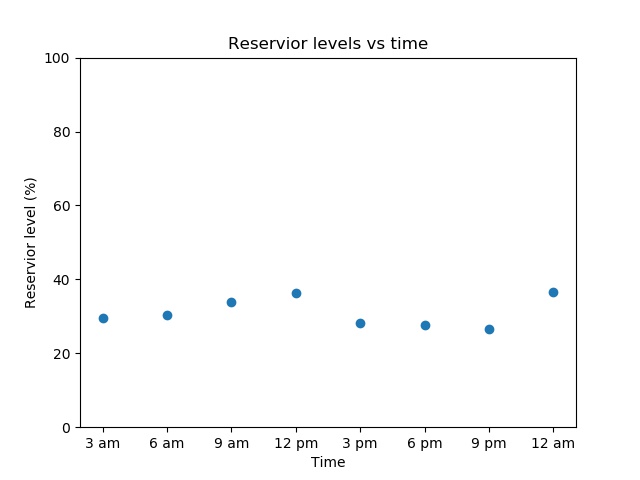
The result may look like this:
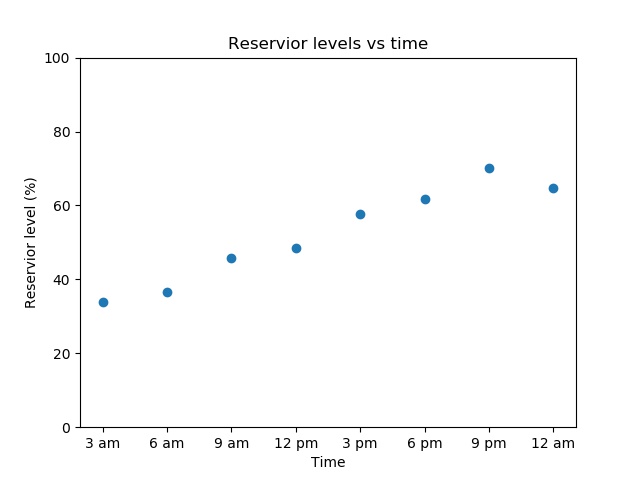
On a day with rain it might look like this:
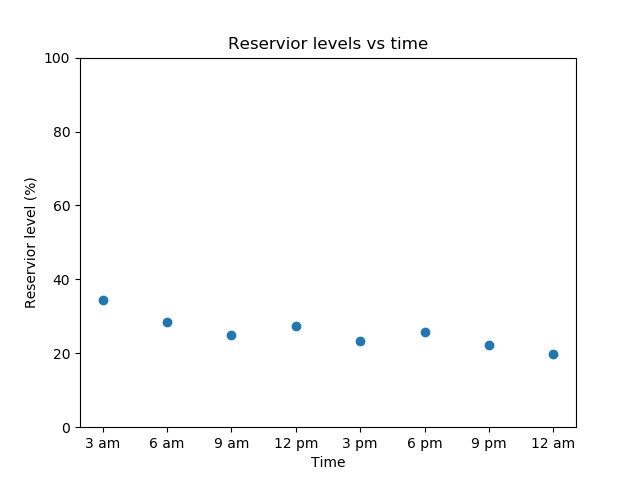
and on a dry day it might look like this:
All of these outputs look very different but are valid. However, if a researcher sees a result like this:
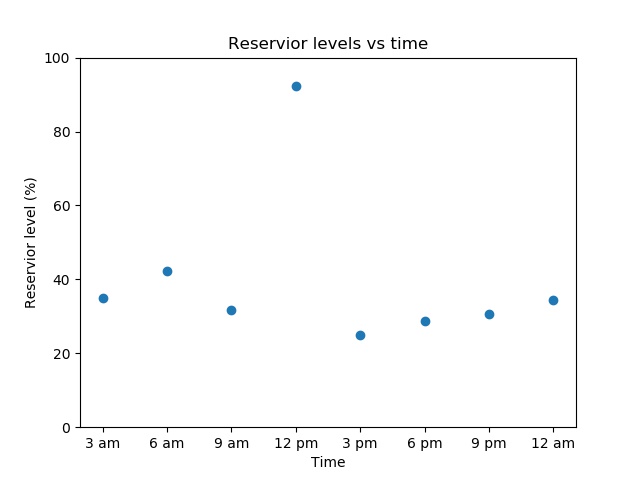
they could easily conclude there is a bug as a lake is unlikely to triple its volume and then lose it again in the space of a few hours. “Eyeballing” tests like these are time-consuming as they must be done by a human. However, the process can be partially or fully automated by creating basic “sanity checks”. For example, the water level at one time should be within, say, 10% of the water level at the previous time step. Another check could be that there are no negative values, as a lake can’t be -30% full. These sort of tests can’t cover every way something can be visibly wrong, but they are much easier to automate and will suffice for most cases.
Testing if non-integer numbers are equal¶
When 0.1 + 0.2 does not equal 0.3¶
There is a complication with testing if the answer a piece of code outputs is equal to the expected answer when the numbers are not integers. Let’s look at this Python example, but note that this problem is not unique to Python.
If we assign 0.1 to a and 0.2 to b and print their sum, we get 0.3, as expected.
>>> a = 0.1
>>> b = 0.2
>>> print(a + b)
0.3If, however, we compare the result of a plus b to 0.3 we get False.
>>> print(a + b == 0.3)
FalseIf we show the value of a plus b directly, we can see there is a subtle margin of error.
>>> a + b
0.30000000000000004This is because floating-point numbers are approximations of real numbers. The result of floating-point calculations can depend upon the compiler or interpreter, processor or system architecture and number of CPUs or processes being used. This can present a major obstacle for writing tests.
Equality in a floating point world¶
When comparing floating-point numbers for equality, we have to compare to within a given tolerance, alternatively termed a threshold or delta. For example, we might consider the calculated and expected values of some number to be equal if the absolute value of their difference is within the absolute value of our tolerance.
Many testing frameworks provide functions for comparing equality of floating-point numbers to within a given tolerance. For example for the framework pytest:
import pytest
a = 0.1
b = 0.2
c = a + b
assert c == pytest.approx(0.3)this passes, but if the 0.3 was changed to 0.4 it would fail.
Unit test frameworks for other languages also often provide similar functions:
- Cunit for C: CU_ASSERT_DOUBLE_EQUAL(actual, expected, granularity)
- CPPUnit for C++: CPPUNIT_ASSERT_DOUBLES_EQUAL(expected, actual, delta)
- googletest for C++: ASSERT_NEAR(val1, val2, abs_error)
- FRUIT for Fortran: subroutine assert_eq_double_in_range_(var1, var2, delta, message)
- JUnit for Java: org.junit.Assert.assertEquals(double expected, double actual, double delta)
- testthat for R:
- expect_equal(actual, expected, tolerance=DELTA) - absolute error within DELTA
- expect_equal(actual, expected, scale=expected, tolerance=DELTA) - relative error within DELTA
- julia:
val1 ≈ val2isapprox(val1, val2, atol=abs_delta, rtol=rel_delta)Test.jlwith≈:@test val1 ≈ val2 atol=abs_delta rtol=rel_delta