
Data curation is one of the key aspects of Research Data Management (RDM). It involves the capturing, appraisal, disposal, description, preservation, access, reuse and transformation of research data. Data curation promotes the use of data from the point of creation to ensuring that its used for the purpose it is intended for. Data curation also enables you to easily access datasets and information that you need in an organised format, once shared in a Data Repository [def]. You can imagine that if you don’t follow the data curation process, it becomes difficult to access that data.
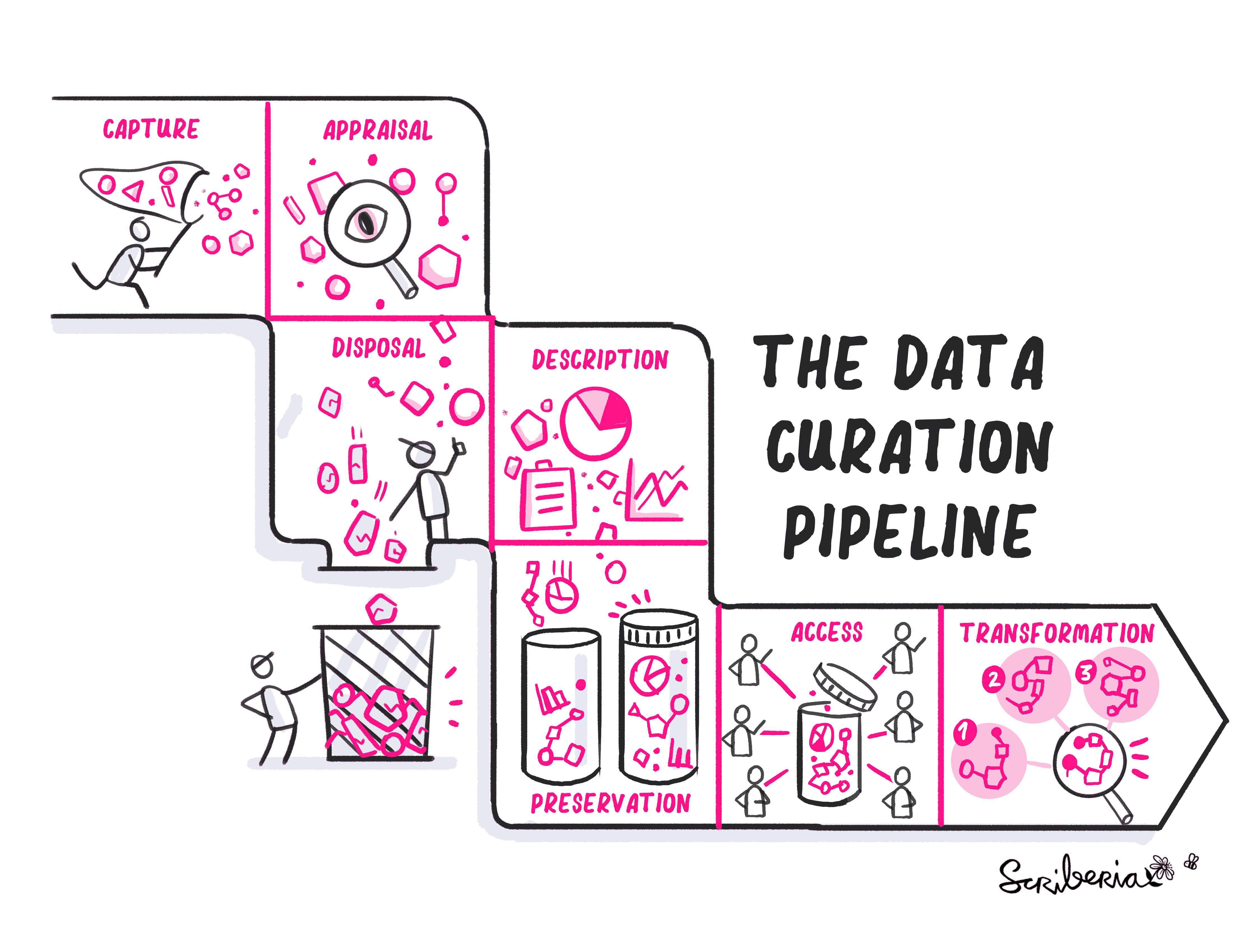
Figure 1:The Data Curation pipeline. The Turing Way project illustration by Scriberia. Zenodo. The Turing Way Community & Scriberia (2024)
Data Curation Pipeline¶
1. Data capture¶
Data capture is the process of gathering or collecting data from different sources, which will be processed and used for certain purposes. These sources may be research articles in electronic format or databases like electronic databases among others. This stage focuses on ensuring that the data captured is actually fit for purpose and ready for curation.
- See Finding data for more information
2. Data appraisal¶
In data appraisal, you are required to select the appropriate data by entering, digitizing, transcribing, checking, validating and cleaning the data. You may also need to anonymise or pseudoanonymise the data where necessary. Your appraisal and selection policy should ensure consistency, transparency, and accountable decision making.
- See Crystal Lewis’s blog on cleaning data for more detailed information.
- Watch DataONE Webinar: Tidying Your Data
3. Data disposal¶
Data disposal involves disposing of data that has not be selected for retention. You need to have an appraisal policy which will guide you on the data required for archiving, redeployment, transfer of custody or ownership or destroying the research data.
4. Data description¶
Data description requires that you are able to interpret the data; derive data; produce research outputs; author publications; data anonymisation; data visualization; data validation and prepare the data for preservation. So it is important that you describe the research data so that it is discoverable and usable over time, Documentation and Metadata for more information. There are also metadata standards that already exist to help you with standardised descriptions.
5. Data preservation¶
See Data Repositories and Sharing and Archiving Data for more information.
6. Data access¶
Data access entails distributing data, sharing data, publishing data, linking data to outputs, controlling access, establishing copyright and promoting or disseminating the data to wider audiences to access it or re-use it.
You can make the data freely available online to anyone who may be interested in reading it or you may restrict access of the data or provide an option of how to access the data.
See Data Repositories and Sharing and Archiving Data for more information.
7. Data transformation¶
Data transformation is the practice of examining large datasets to generate new information. You can reanalyze the research data and make relationships that may not have been previously discovered.
Additional resources on data curation¶
- The Turing Way Community, & Scriberia. (2024). Illustrations from The Turing Way: Shared under CC-BY 4.0 for reuse. Zenodo. 10.5281/ZENODO.3332807
- Arguillas, F., Christian, T.-M., Gooch, M., Honeyman, T., & Peer, L. (2022). 10 Things for Curating Reproducible and FAIR Research. Research Data Alliance. 10.15497/RDA00074