In this chapter, we will create a Binder project from scratch: we will first make a repository on GitHub and then launch it on mybinder.org. Sections where you are expected to complete a task are denoted by three traffic light 🚦 emojis. Some steps give you the option of Python, Julia or R - click on the tab of your preferred language.
Requirements¶
You will need:
- Some code and some data. The code should take less than 10 minutes to run, and the data should be less than 10 MB. This might mean that you just pick one script from a bigger project, or bring a subset of your data. Note that it’s really important that the code and data can be made public because we’ll be using the public binder instance.
- A GitHub account.
Please sign up for one if you don’t already have one: https://
github .com /join
1. Creating a repo to Binderize¶
🚦🚦🚦
- Create a new repo on GitHub called “my-first-binder”
- Make sure the repository is public, not private!
- Don’t forget to initialise the repo with a README!
- Create a file called
hello.pyvia the web interface withprint("Hello from Binder!")on the first line and commit to themainbranch
Create a new repo on GitHub called “my-first-binder”
- Make sure the repository is public, not private!
- Don’t forget to initialise the repo with a README!
Create a file called
hello.jlvia the web interface withprintln("Hello from Binder!")on the first line and commit to themainbranchCreate a file called
Project.toml(WARNING: the capitalisation is important!) with the following content and commit it tomain. This will install Julia into the Binder environment.[compat] julia = "1.3"
Create a new repo on GitHub called “my-first-binder”
- Make sure the repository is public, not private!
- Don’t forget to initialise the repo with a README!
Create a file called
hello.Rvia the web interface withprint("Hello from Binder!")on the first line and commit to themainbranchCreate a file called
runtime.txtwithr-2022-01-01on the first line. This date represents the snapshot of CRAN hosted on the RStudio Package Manager we will use. Commit this file to themainbranch.
Why does the repo have to be public?¶
mybinder.org cannot access private repositories as this would require a secret token. The Binder team choose not to take on the responsibility of handling secret tokens as mybinder.org is a public service and proof of technological concept. If accessing private repositories is a feature you/your team need, we advise that you look into building your own BinderHub.
2. Launch your first repo!¶
🚦🚦🚦
- Go to https://
mybinder .org - Type the URL of your repo into the “GitHub repo or URL” box.
It should look like this:
- As you type, the webpage generates a link in the “Copy the URL below...” box
It should look like this:
https://
mybinder .org /v2 /gh /YOUR -USERNAME /my -first -binder /HEAD - Copy it, open a new browser tab and visit that URL
- You will see a “spinner” as Binder launches the repo
If everything ran smoothly, you’ll see a JupyterLab interface.
What’s happening in the background? - Part 1¶
While you wait, BinderHub (the backend of Binder) is:
- Fetching your repo from GitHub
- Analysing the contents
- Building a Docker image based on your repo
- Launching that Docker image in the cloud
- Connecting you to it via your browser
3. Run the script¶
🚦🚦🚦
- From the launch panel, select “Terminal”
- In the new terminal window, type
python hello.pyand press return
- From the launch panel, select “Terminal”
- In the new terminal window, type
julia hello.jland press return
- From the launch panel, select “Terminal”
- In the new terminal window, type
Rscript -e 'source("hello.R")'and then press return
Hello from Binder! should be printed to the terminal.
4. Pinning Dependencies¶
It was easy to get started, but our environment is barebones - let’s add a dependency!
🚦🚦🚦
- In your repo, create a file called
requirements.txt - Add a line that says:
numpy==1.25.0 - Check for typos! Then commit to the
mainbranch - Visit https://
mybinder .org /v2 /gh /YOUR -USERNAME /my -first -binder /HEAD again in a new tab
In your repo, edit the
Project.tomlfileAdd a new block that says:
[deps] CSV = "336ed68f-0bac-5ca0-87d4-7b16caf5d00b"Check for typos! Then commit to
main.Visit https://
mybinder .org /v2 /gh /YOUR -USERNAME /my -first -binder /HEAD again in a new tab
- In your repo, create a file called
install.R - Add a line that says:
install.packages("readr") - Check for typos! Then commit to the
mainbranch - Visit https://
mybinder .org /v2 /gh /YOUR -USERNAME /my -first -binder /HEAD again in a new tab
This time, click on “Build Logs” in the big, horizontal, grey bar. This will let you watch the progress of your build. It’s useful when your build fails or something you think should be installed is missing.
What’s happening in the background? - Part 2¶
This time, BinderHub will read the configuration file you added and install the specific version of the package you requested.
More on pinning dependencies¶
In the above example, we used two equals signs (==) to pin the version of numpy.
This tells Binder to install that specific version.
Another way to pin a version number is to use the greater than or equal to sign (>=) to allow any version above a particular one to be installed.
This is useful when you have a lot of dependencies that may have dependencies on each other and allows Binder to find a configuration of your dependencies that do not conflict with one another whilst avoiding any earlier versions which may break or change your code.
Finally, you could not provide a version number at all (just the name of the library/package) and Binder will install the latest version of that package.
In the above example, we copied a hash into our Project.toml file which is related to the version of the package we’d like to install.
For a full dependency graph, we would also need to include a Manifest.toml file which would document dependencies of dependencies.
Between these two files, we are able to instantiate an exact replication of a Julia environment.
Of course we can imagine that, as the environment grows and the inter-dependencies become more complex, it would become very taxing to write these files by hand!
The truth is that you’d never do it manually, the built-in package manager Pkg can generate them automatically.
In the above example, we specified that we want to use R in our project by including a date in runtime.txt.
The date tells Binder which CRAN snapshot to source R and packages from.
These snapshots are sourced from the RStudio Package Manager (RSPM).
In the above example, the RSPM snapshot dated r-2022-01-01 is used and the version of R and readr available at that date and installed.
For the example workflow to work correctly, please ensure you do not supply a date earlier than this example date.
This provides some rudimentary package versioning for R users but is not as robust as pinning versions in a requirements.txt in Python.
For more robust and specific version pinning in R, have a look at the renv package.
5. Check the Environment¶
🚦🚦🚦
From the launch panel, select “Python 3” from the Notebook section to open a new notebook
Type the following into a new cell:
import numpy print(numpy.__version__) numpy.random.randn()Run the cell to see the version number and a random number printed out
- Press either SHIFT+RETURN or the “Run” button in the Menu bar
From the launch panel, select “Julia” from the Notebook section to open a new Julia notebook
Type the following into a new cell:
using Pkg Pkg.status()Run the cell to see the version number printed out
- Press either SHIFT+RETURN or the “Run” button in the Menu bar
From the launch panel, select “R” from the Notebook section to open a new R notebook
Type the following into a new cell:
library(readr) packageVersion("readr") read_csv(system.file("extdata/mtcars.csv", package = "readr"))Run the cell
- Press either SHIFT+RETURN or the “Run” button in the Menu bar
You should see the following output:
- the version number of the installed version of
readr - a tibble of the contents of the
mtcars.csvwhich is a csv file included in packagereadr
- the version number of the installed version of
- Press either SHIFT+RETURN or the “Run” button in the Menu bar
You should see the following output:
6. Sharing your Work¶
Binder is all about sharing your work easily and there are two ways to do it:
- Share the https://
mybinder .org /v2 /gh /YOUR -USERNAME /my -first -binder /HEAD URL directly - Visit https://
mybinder .org, type in the URL of your repo and copy the Markdown or ReStructured Text snippet into your README.mdfile. This snippet will render a badge that people can click, which looks like this:
🚦🚦🚦
- Add the Markdown snippet from https://
mybinder .org to the README.mdfile in your repo- The grey bar displaying a binder badge will unfold to reveal the snippets. Click the clipboard icon next to the box marked with “m” to automatically copy the Markdown snippet.
- Click the badge to make sure it works!
7. Accessing data in your Binder¶
Another kind of dependency for projects is data. There are different ways to make data available in your Binder depending on the size of your data and your preferences for sharing it.
Small public files¶
The simplest approach for small, public data files is to add them directly into your GitHub repository. They are then directly encapsulated into the environment and versioned along with your code.
This is ideal for files up to 10MB.
Medium public files¶
To access medium files from a few 10s MB up to a few hundred MB, you can add a file called postBuild to your repo.
A postBuild file is a shell script that is executed as part of the image construction and is only executed once when a new image is built, not every time the Binder is launched.
See Binder’s postBuild example for more uses of the postBuild script.
Large public files¶
It is not practical to place large files in your GitHub repo or include them directly in the image that Binder builds. The best option for large files is to use a library specific to the data format to stream the data as you’re using it or to download it on demand as part of your code.
For security reasons, the outgoing traffic of your Binder is restricted to HTTP/S or GitHub connections only. You will not be able to use FTP sites to fetch data on mybinder.org.
Private files¶
There is no way to access files which are not public from mybinder.org. You should consider all information in your Binder as public, meaning that:
- there should be no passwords, tokens, keys and so on in your GitHub repo;
- you should not type passwords into a Binder running on mybinder.org;
- you should not upload your private SSH key or API token to a running Binder.
In order to support access to private files, you would need to create a local deployment of BinderHub where you can decide the security trade-offs yourselves.
8. Get data with postBuild¶
🚦🚦🚦
- Go to your GitHub repo and create a file called
postBuild - In
postBuild, add a single line reading:wget -q -O gapminder.csv http://bit.ly/2uh4s3gwgetis a program which retrieves content from web servers. This line extracts the content from the bitly URL and saves it to the filename denoted by the-Oflag (capital “O”, not zero), in this casegapminder.csv. The-qflag tellswgetto do this quietly, meaning it won’t print anything to the console.
- Update your
requirements.txtfile by adding a new line withpandason it and another new line withmatplotlibon it- These packages aren’t necessary to download the data but we will use them to read the CSV file and make a plot
- Click the binder badge in your README to launch your Binder
Once the Binder has launched, you should see a new file has appeared that was not part of your repo when you clicked the badge.
Now visualise the data by creating a new notebook (selecting “Python 3” from the Notebook section) and run the following code in a cell.
%matplotlib inline
import pandas
data = pandas.read_csv("gapminder.csv", index_col="country")
years = data.columns.str.strip("gdpPercap_") # Extract year from last 4 characters of each column name
data.columns = years.astype(int) # Convert year values to integers, saving results back to dataframe
data.loc["Australia"].plot()Go to your GitHub repo and create a file called
postBuildIn
postBuild, add a single line reading:wget -q -O gapminder.csv http://bit.ly/2uh4s3gwgetis a program which retrieves content from web servers. This line extracts the content from the bitly URL and saves it to the filename denoted by the-Oflag (capital “O”, not zero), in this casegapminder.csv. The-qflag tellswgetto do this quietly, meaning it won’t print anything to the console.
Update your
Project.tomlfile by adding new dependencies to[deps]with the following lines:DataFrames = "a93c6f00-e57d-5684-b7b6-d8193f3e46c0" Plots = "91a5bcdd-55d7-5caf-9e0b-520d859cae80"- These packages aren’t necessary to download the data but we will use them to read the CSV file and make a plot
Click the binder badge in your README to launch your Binder
Once the Binder has launched, you should see a new file has appeared that was not part of your repo when you clicked the badge.
Now visualise the data by creating a new notebook (selecting “Julia” from the Notebook section) and run the following code in a cell.
using DataFrames
using CSV
using Plots
data = CSV.read("gapminder.csv", DataFrame)
# Extract the row corresponding to Australia
aus_gdp = data[data[:, :country] .== "Australia", :]
aus_gdp = Matrix(aus_gdp[:,2:end])[:] # as vector
# Extract the years as Ints from the column names
years = [x[end-3:end] for x in names(data)[2:end]]
years = parse.(Int, years)
# Plot
plot(years, aus_gdp)Go to your GitHub repo and create a file called
postBuildIn
postBuild, add a single line reading:wget -q -O gapminder.csv http://bit.ly/2uh4s3gwgetis a program which retrieves content from web servers. This line extracts the content from the bitly URL and saves it to the filename denoted by the-Oflag (capital “O”, not zero), in this casegapminder.csv. The-qflag tellswgetto do this quietly, meaning it won’t print anything to the console.
Update your
install.Rfile to install two additional dependencies,"tidyr"and"ggplot2". To do so, supply a character vector of the required packages toinstall.packages()instead of a single character string. The installation command should now look like this:install.packages(c("readr", "tidyr", "ggplot2"))- These packages aren’t necessary to download the data but we will use them to read the CSV file, process it and make a plot
Click the binder badge in your README to launch your Binder
Once the Binder has launched, you should see a new file has appeared that was not part of your repo when you clicked the badge.
Now visualise the data by creating a new notebook (selecting “R” from the Notebook section) and running the following code in a cell.
library(readr)
library(tidyr)
library(ggplot2)
data <- read_csv("gapminder.csv") %>%
pivot_longer(-country,
names_to = "year",
values_to = "gdpPercap",
names_prefix = "gdpPercap_",
names_transform = list(year = as.integer))
data[data$country == "Australia", ] %>%
ggplot(aes(x = year, y = gdpPercap)) +
geom_line()Changing the Interface¶
Throughout this tutorial, we have been using the JupyterLab interface. This is the default interface for newly created Binder instances. However, this is not the only interface available on mybinder.org, the Classic Notebook view and RStudio are available too. (An R environment needs to be installed for RStudio to be available.)
You can access the different interfaces in different ways. The easiest way is to use the buttons in the JupyterLab Launcher, but you can provide URL parameters to directly open a specific interface (or file!) when the Binder instance launches. We’ll now cover three ways you can manipulate your Binder URL to navigate between interfaces.
from inside a running Binder¶
Here is the structure of the URL inside a running Binder instance running JupyterLab:
https://.mybinder.org/user/<a composite of your username, your repo name and a hash>/lab
You can change the interface from JupyterLab to either the Classic Notebook or RStudio by changing the /lab part of the URL to:
- Classic Notebook:
/tree - RStudio:
/rstudio
by changing the mybinder.org launch link¶
Here is the launch link you have been using throughout this tutorial:
https://
mybinder .org /v2 /gh /YOUR -USERNAME /my -first -binder /HEAD
You can access each interface by appending one of the following to the end of you URL:
- Jupyter Notebook:
?urlpath=tree - JupyterLab:
?urlpath=lab - RStudio:
?urlpath=rstudio
by using the mybinder.org form¶
You can also set the interface when constructing your launch link on the mybinder.org website (instead of editing the URL directly) as demonstrated in the below gif.
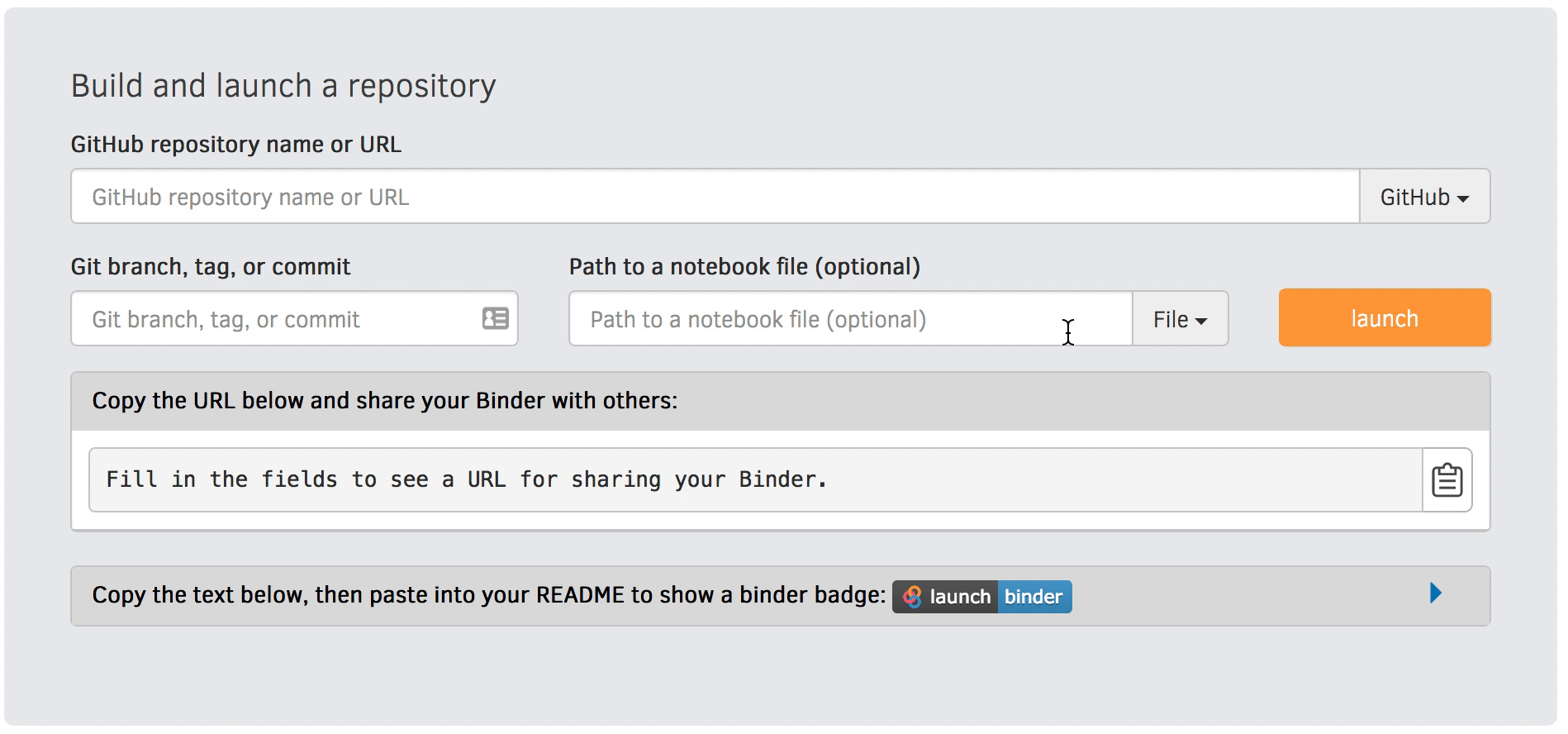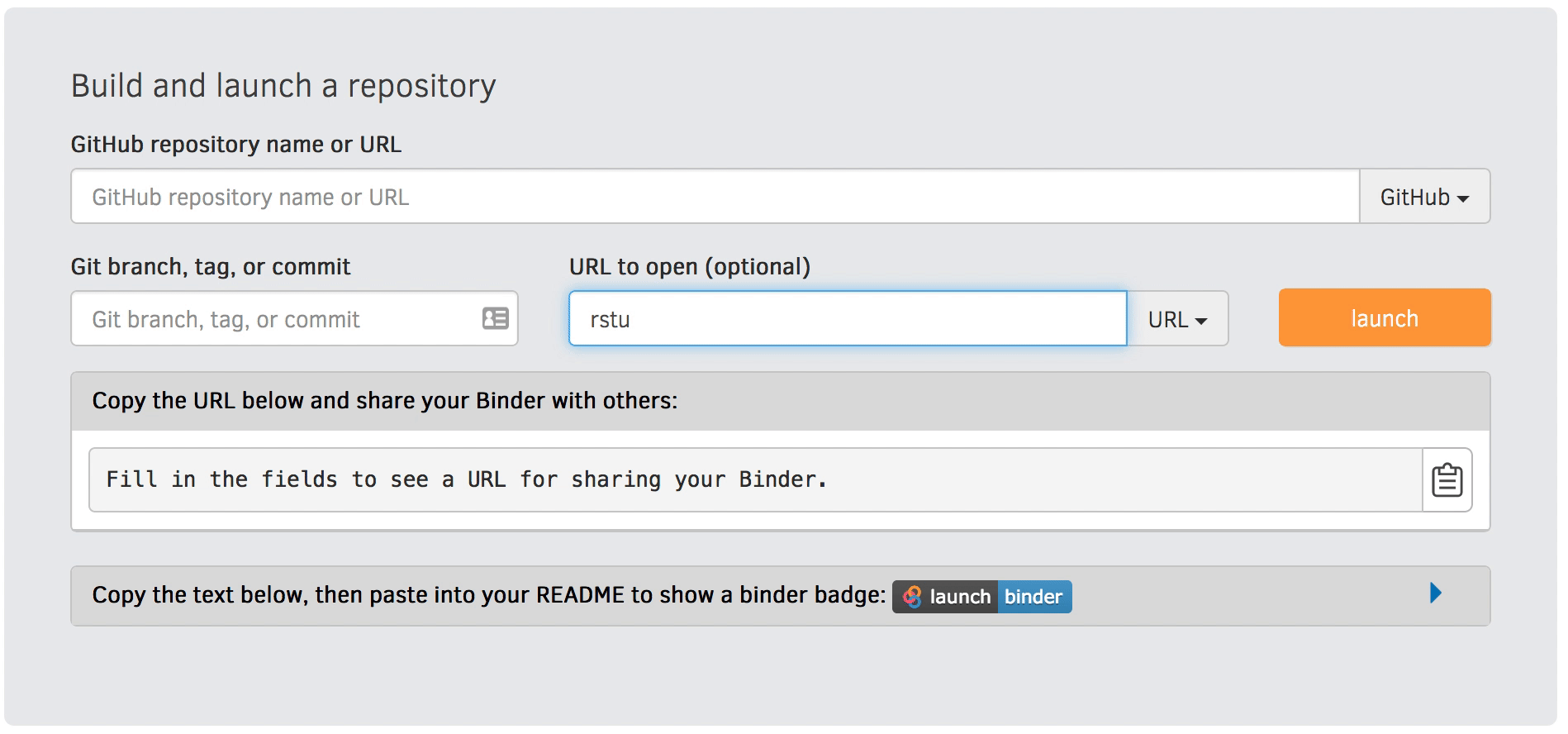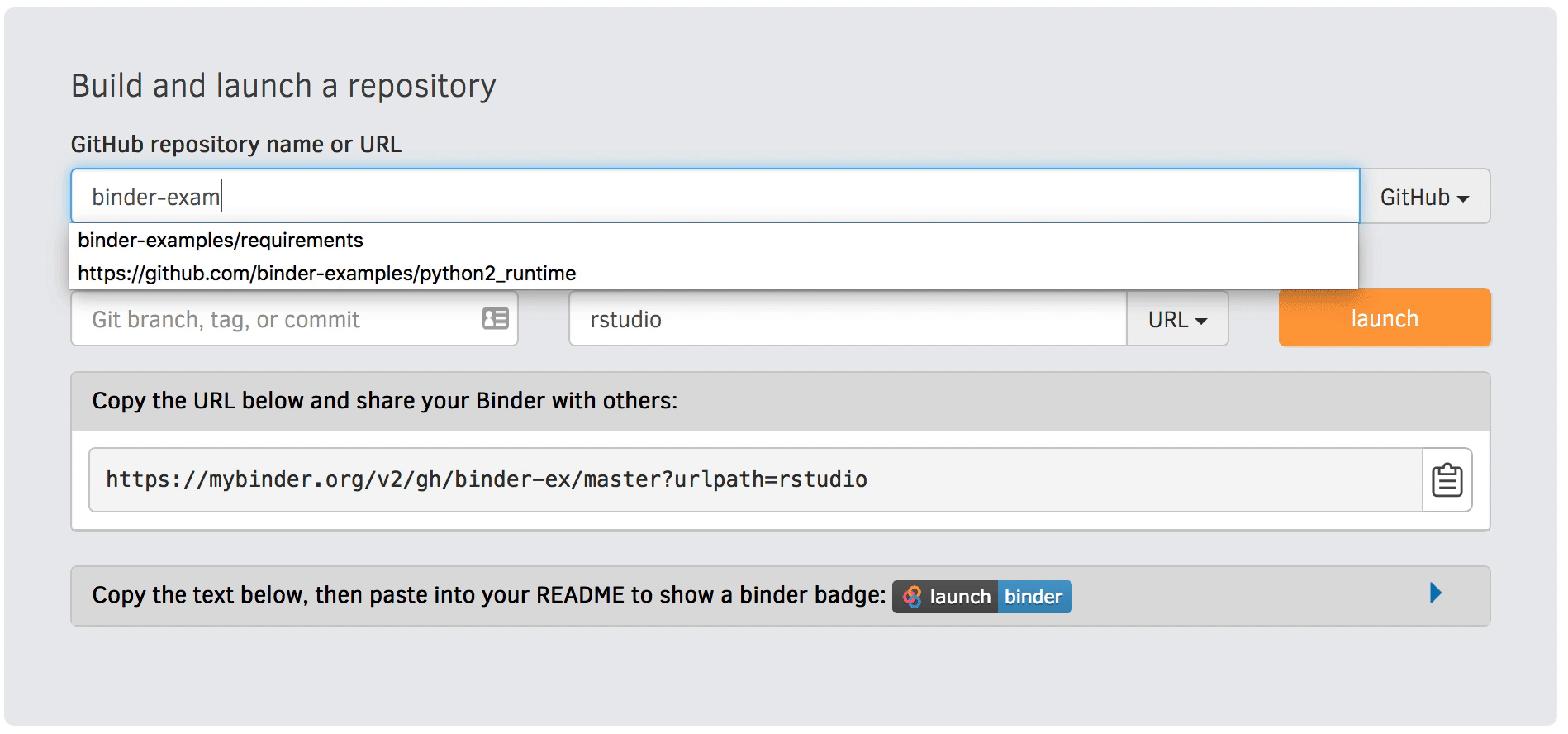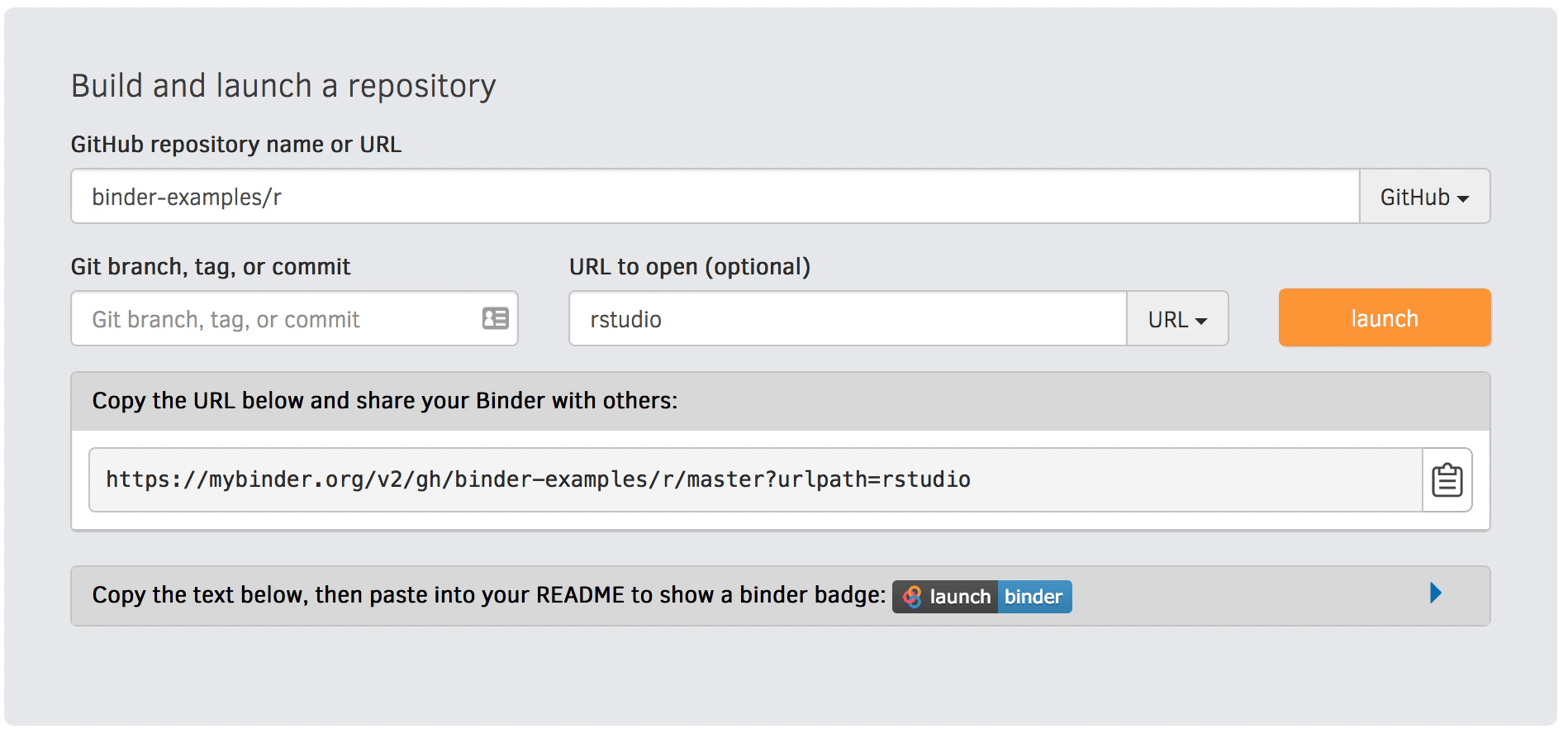
Figure 1:Use the “URL to open” option on the mybinder.org site to select your interface
Now over to you!¶
Now you’ve binderized (bound?) this demo repo, it’s time to binderize the example script and data you brought along!
Some useful links:
- Choosing languages:
- Configuration files:
- Example Binder repos:
- Getting data:
- With
wget: https://github .com /binder -examples /getting -data - With
quilt: https://github .com /binder -examples /data -quilt - From remote storage: https://
github .com /binder -examples /remote _storage
- With
Advanced usage patterns:
- Separating content from environment with
nbgitpullerto reduced rebuilds: - Tips for reducing the start-up time of your repository: