A Machine Learning (ML) pipeline consists of a series of activities including the collection of data, training of an ML model, and the deployment of the model into use. Data is integral throughout the ML process and the methods for which data is collected, annotated, processed, and shared will impact individuals and communities who may be represented in or the creators of the data, as well as data users who would like access to the data.
In addition to the technical decisions and team members involved in data governance, it is also important to think about the wider community involved in an ML project, including the data contributors, data subjects, data stewards, data annotators, and communities impacted by the model outputs. When possible, a ML team should consider how this wider community can be involved in data, model, and project governance. This can empower more people involved in and impacted by the machine learning pipeline and ensure more effective, sustainable, and equitable practices. The following framework can support the understanding of different community governance opportunities in the ML pipeline.
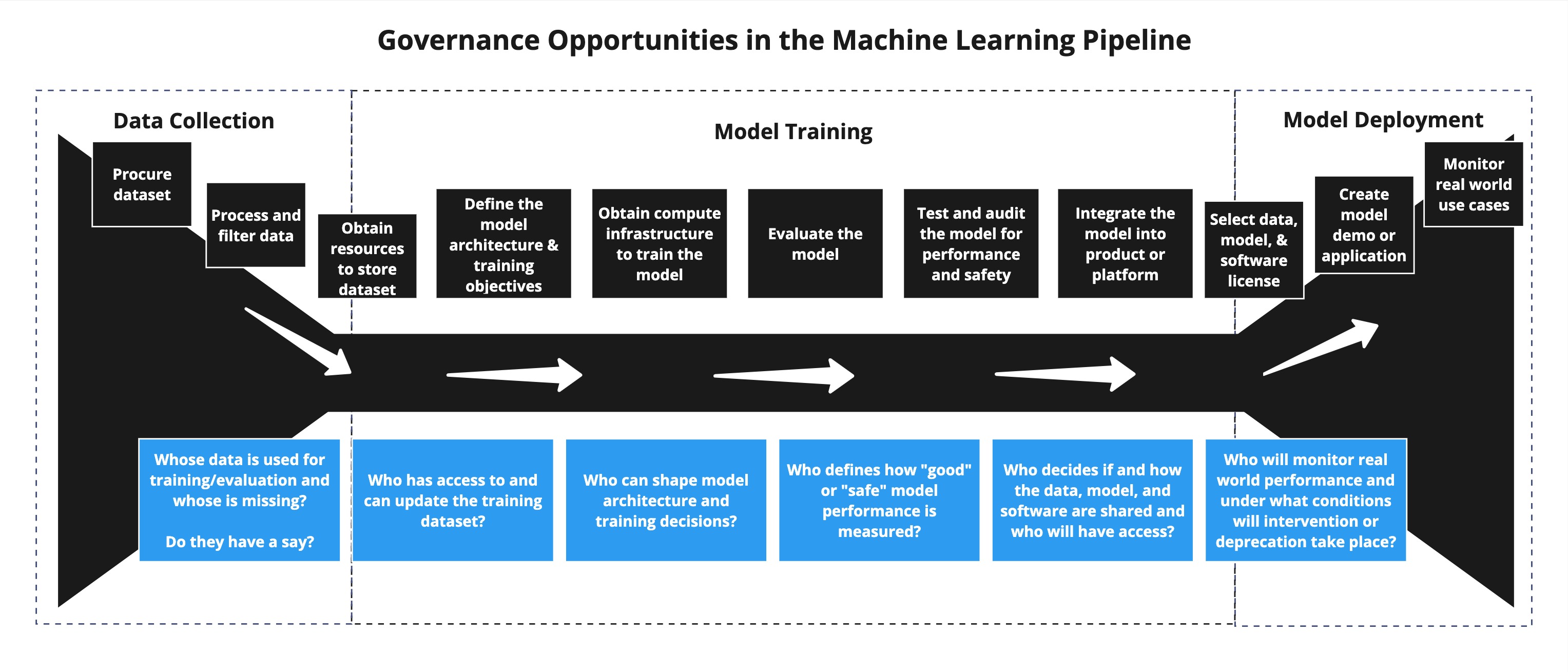
Figure 1:Governance Opportunities in the Machine Learning Pipeline. Used under a CC-BY 4.0 licence. DOI: 10
This chapter will cover examples of data governance practices for ML for different steps in the pipeline, which may include but not be exclusive to:
- Data Collection
- Data Management
- Data Processing
Data Collection¶
Many ML models are trained using datasets collected by a research team, which may be proprietary, or by using an open dataset that is available for download (sometimes with restrictions on its usage, such as only being available for use in academic settings). The deep learning (DL) family of models, in particular, relies on massive corpuses of data such as text, code, images, sound, and other media. The process of data collection depends on the type and volume of data required and sources for acquisition. For example, a project that uses patient health record data versus a project that uses a dataset of millions of social media posts will require different processes for gaining access to data as well as actually collecting and storing the data. Many DL models rely on data scraped from the internet due to the sheer volume of digital content that is available on the web. For example, ImageNet datasets are sourced from web images from image hosting websites like Flickr, and LAION datasets come from web crawling sources like Common Crawl. These methods of data collection through web scraping have raised issues regarding data quality and bias due to the nature of using uncurated Internet data, as well as issues of data rights as web scraped data sets often include copyrighted data or data obtained without consent that may be in violation of the data license and terms of use. To address issues related to respecting data licenses, ML teams should be mindful of using data only when compatible with the license, including open source or permissively licensed data. This can be challenging to accomplish with data that does not have explicit licenses, or for data scraped from the web which may not have the license included in the metadata.
Governance Tool: Datasheets for Datasets¶
Datasheets are resources accompanying datasets that can provide key information about the motivation to create the dataset, the data collection process, the dataset composition and pre-processing, and legal and ethical considerations when using the data. Datasheets help contextualise the resource and are an opportunity for dataset creators to share any concerns, suggestions, and other advice regarding responsible use of the dataset. The Datasheets for Datasets paper contains a list of example questions that data creators should ask themselves and document in their datasheet.
Data Management¶
Once data collection is complete, challenges emerge around data storage, access, and making changes to the dataset. Because state-of-the-art ML datasets are very large, they tend to be stored in a central location, often a cloud provider database, and made available for download under certain circumstances. In addition to creating a governance structure for managing access to the dataset to certain users, there is also the challenge of creating a governance structure to allow data creators to request to opt-out their data from the dataset, if the team is interested in providing that capability. Because opting out occurs after a dataset has already been created, it will not remove the data from original versions of the dataset, but can facilitate removal from future versions.
Governance Tool: Am I In the Stack?¶
This tool was developed by the BigCode team to help developers inspect The Stack dataset so they can see whether any of their repositories have been included and might be used for training ML models. If that is the case and they would prefer for their data to be removed, developers receive a custom link on the Am I In the Stack? website that automatically generates an issue in the BigCode opt-out repository for an official opt-out request. You can choose which repos you’d like to remove, as well as your commits and issues. After submitting the issue, your request is added to the queue for removal from all future iterations of The Stack.
Governance Tool: Have I Been Trained?¶
This tool was developed by Spawning to help artists check if their work is a part of common datasets used to train AI art models and to opt-in or opt-out to future training. They maintain a “registry of non-consenting data” where individuals and companies can check to see if their data is a part of these datasets.
Data Processing¶
In order to address some of the problematic aspects of datasets, such as biased or harmful content or existence of personal information, some data processing should be done before the dataset is used for model training, released to a wider audience, or ideally, even before stored on a database. Addressing these data quality and privacy issues may be motivated by regulatory compliance like GDPR or a team’s norms and best practices. Because this work, particularly identifying and removing harmful content, may be contextual or reliant on the expertise of specific communities, these tasks should be performed in collaboration with community experts. As an example, when identifying sensitive information for removal from a dataset, a team may identify clear targets regarding an individual’s data such as usernames, passwords, and emails. However, a community from a specific country, or who speak a specific language, or who face a specific disability or form of discrimination may be able to identify additional criteria that should be removed to protect their community members. Individuals from specific geographical or language contexts may also provide expertise on what metadata, such as source attribution or permitted use cases, can support informed and responsible use of a dataset.
Governance Tool: BigScience Catalogue of Language Data and Resources¶
The catalogue visualises through an interactive world map the 192 data sources gathered as part of the BigScience project and its natural language text dataset. Through organized public hackathons with resource custodians from around the world, the team collected metadata on 432 different language tags associated with the dataset (each entry can have multiple language tags). The metadata added, such as language location, resource custodian and contact, and license type, was based on the expertise of the local residents and resource experts (primarily librarians) who can provide essential information on the context and content on data in their language. Learn more about the methodology from their paper: Documenting Geographically and Contextually Diverse Data Sources: The BigScience Catalogue of Language Data and Resources.
Governance Tool: PII Redaction Dataset¶
Filtering out Personally Identifiable Information (PII) such as email addresses and passwords is an important data processing set. Rather than trying to remove this information from trained model weights after the fact, which is an open technical challenge, teams can choose to remove PII from the datasets before training. In order to perform automated PII redaction, it can help to build a dataset of PII that can be used to develop a rules-based or classifier-based approach to removing PII. In practice, the BigCode project found that neither regular expression-based approaches or commercial software for PII detection met their performance requirements, so they collaborated with Toloka crowd-workers to curate and annotate a PII in source code dataset. This dataset is available to approved individuals, researchers, and developers who are granted access to use this for their own R&D, as long as they uphold ethical standards and data protection measure. To learn more about this work with Toloka crowd workers, read their blog post on the collaboration.